More and more academic libraries have invested in discovery layers, the centralized “Google-like” search tool that returns results from different services and providers by searching a centralized index. The move to discovery has been driven by the ascendence of Google as well as libraries' increasing focus on user experience. Unlike the vendor-specific search tools or federated searches of the previous decade, discovery presents a simplified picture of the library research process. It has the familiar single search box, and the results are not broken out by provider or format but are all shown together in a list, aping the Google model for search results.
Discovery's promise of a simple search experience works for users, more often than not. But discovery's external simplicity hides a complex system running in the background, making decisions for our users. And it is the rare user that questions these decisions. As Sherry Turkle (1997) observed, users approach complex systems like search engines at “interface value.” Since the interface is simple, they are content to assume that the underlying mechanism that makes them work is also simple. They are often unaware that complex algorithms help determine what results are shown and what results are excluded. As library search in particular has become simpler, the complex workings of our search tools have, like Google's, receded into a black box. As Tim Sherratt (2016) reminds us “it's not just the simplicity of that single search box, it's our faith that search will just work.”
Even within libraries, algorithms are not well understood. A common definition is that an algorithm is a set of instructions that take an input and produces an output. But translating this simple definition into a model that explains how a single search box can produce millions of possible results is a challenge. Describing an algorithm in these terms is another attempt to put a simple interface on a complex idea. Frankly, with algorithms, the input and output aren't the most important parts. The instructions are what matter, since they help to determine how the input is interpreted and how the output will be generated. Perhaps a better way to define algorithms is by following Christopher Steiner (2012), who compared them to “decision trees, wherein the resolution to a complex problem, requiring consideration of a large set of variables, can be broken down to a long string of binary choices” (p. 6). An algorithm, then, can be thought of as a series of if/then statements, where a number of parameters are examined and the results can affect how the input is transformed along the way. Algorithms don't have to be computer code, either. As a child I loved the Choose Your Own Adventure series, and they were in their own way a literary algorithm. Today, what stories appear on your Facebook news feed and what ads you're shown as you move about the web are all determined by algorithms.
But rather than objective methods of analysis, algorithms are systematic instructions created by humans that computers follow. Ian Bogost (2015), writing in The Atlantic, claims that algorithms are closer to caricatures then deities. Algorithms, he writes,“ take a complex system from the world and abstracted into the processes that capture some of that systems logic and discard others.” This is important to remember, however, because our view of algorithms as objective processes is dependent on the absence of human interference. But as Andreas Ekström (2015) reminds us in his TED talk, The Moral Bias Behind your Search Results, “behind every algorithm is always a person, a person with a set of personal beliefs that no code can ever completely eradicate.” We might add that behind every algorithm is also a company, with obligations to its business model and shareholders.
To the extent that we understand algorithms, they take on a more significant role than simply a set of instructions a computer uses to weight the “relevance” of possible results. As Tarlton Gillespie (2014) has noted, “more than mere tools, algorithms are also stabilizers of trust, practical and symbolic of assurances that their evaluations are fair and accurate, free from subjectivity, error, or attempted influence” (p. 179). Users' faith in search algorithms frees us from having to evaluate the inner workings and possible biases of tools that have become fixtures in our daily lives. The French philosopher Bruno Latour has said that “in so far as they consider all the black boxes well sealed, people do not, any more than scientists, live in a world of fiction, representation, symbol, approximation, convention… they are simply right” (qtd. in Dormehl, 2014, p. 236).
Providers also capitalize on this faith. Marissa Mayer, while at Google, said, “It’s very, very complicated technology, but behind a very simple interface. Our users don't need to understand how complicated the technology and the development work that happens behind us is. What they do need to understand is that they can just go to a box, type what they want, and get answers” (Vaidhyanathan 2011, p. 54). That our perception of search tools’ trustworthiness should be so uncritical has been a boon to the industry. In librarianship over the past few decades, the profession has had to grapple with the perception that computers are better at finding relevant information then people. On the technical services side of the profession, we have responded to this perception by pushing for more integration with our various search tools. Over the past decade discovery tools, which search a unified index of providers from a single certain point, have changed the way that many library users do research. As our discovery tools have become more complex, much of the discussion and critique has centered on the simplification of the search process, the effectiveness of user interface elements, and the integration with other library systems and services. I have found no substantive evaluation of the search algorithms of commercial library discovery platforms in the literature.
The task of determining how successful our library discovery tools are at presenting good results is thus stymied by user perceptions of what the tools are capable of, the opacity of the business model of our search engine providers, and the fact that underlying everything was a series of instructions written by people with a particular point of view. Yet as academic libraries providing our users with search tools, we need a way to evaluate the contents of the results. In Safiya Noble's (2012) research on commercial search engines like Google, she highlights how the results Google shows users are understood themselves to be a reflection of the truth. When students in Noble's classes search for “black girls” and Google returns porn websites (p. 38), what are African-American girls to think about their own identity? In situations like this, we can make a clear argument that the results are not only not relevant, but that they appear to be biased. But Google's results for “black girls” also highlights the moral question underneath this: if indeed algorithms are created by people with biases and perspectives, who should be accountable for these kinds of search results? (Google often defers to the algorithm, refusing to accept blame since the computer has done the selecting. They fail to mention that engineers programmed the computer to do the selecting in the first place (Dormehl, 2014, p. 226).)
In academia, we like to assume that our results do not necessarily send the same message to users as those of commercial search engines. While Google is showing you “answers,” academic discovery tools are reflecting the scholarly conversation around a subject, and so wide ranges of opinions are to be expected. (It is doubtful that our users are as confident in this distinction as library folk are.) With the number of results that are returned from our commercial discovery services (easily over a hundred thousand on many of the most common searches) along with the trouble in ascertaining the meaning of “relevance,” it can be a challenge to make a solid case for what constitutes a “good” algorithm. But just because this kind of analysis is challenging, or that doing it might call into question our own faith in the objectivity of our discovery service's algorithms, doesn't mean we should abandon it. As the law professor Danielle Citron has argued, “we trust algorithms because we think of them as objective, whereas the reality is that humans craft those algorithms and can embed in them all sorts of biases and perspectives” (as cited in Dormehl, 2014, p. 150). We need to evaluate these algorithms for accuracy and bias.
From following the discussions at professional conferences, on list-servs, and in the professional literature over the past few years, I've seen a sort of acceptance from librarians of the black box nature of our discovery search algorithms. Like our users, by not questioning how the black box works, we can continue to keep have full trust and it's effectiveness. Of course, it is also difficult to test the “effectiveness” of many of our search tools, since the results are often sorted by “Relevance”. The problem with evaluating relevance, is that once you start to measure the relevance of a result you bump up against an important question that is not part of the library discovery service: relevance to whom?
Introducing the concept of relevance automatically brings the supposed objectivity of algorithms into question. In Tarleton Gillespie's (2014) analysis of the “political valence” of algorithms, he cites six dimensions of algorithms that we can examine that have political or moral dimensions. The third and fourth dimensions are “the evaluation of relevance” and “the promise of objectivity” (p.168). As Introna and Nissenbaum (2000) have noted in their work on the politics of search engines, “experts must struggle with the challenge of approximating a complex human value (relevancy) with a computer algorithm” (p.174). Gillespie's (2014) analysis is less optimistic about the engineering attempts at relevancy: “'relevant' is a fluid and loaded judgment … engineers must decide what looks 'right' and tweak their algorithm to attain that result… or make changes based on evidence from their users, treating quick clicks and no follow-up searches as an approximation, not of relevance exactly, but of satisfaction” (p.175).
At Grand Valley State University, we have used the Summon Discovery service from ProQuest since 2009. In 2013, Summon rolled out its new “2.0” product, with a number of features that were meant to move it beyond just the traditional rows and rows of relevance-ranked results. One of those new features was similar to new work coming out of Google around the same time. In Summon 2.0, the right hand sidebar was reserved on new searches for something called the “Topic Explorer.” Topic Explorer was designed to “dynamically display background information for more than 50,000 topics” (ProQuest, 2013) by showing reference articles for the topic the user was searching for. The reference articles would “provide users with valuable contextual information to improve research outcomes” (Ibid). ProQuest did this by “analyzing global Summon usage data and leveraging commercial and open access reference content, as well as librarian expertise” to establish “large-scale, data-driven contextual guidance” (Ibid).
Behind the corporate lingo, the goal of Topic Explorer was to show reference material for broad searches by drawing on entries from Wikipedia, Credo Reference, Gale Virtual Reference Library, and more. At GVSU, we’ve had Wikipedia and Gale Virtual Reference Library enabled since we went live in early 2014.
The Topic Explorer also benefitted from another Summon 2.0 feature: query expansion. Since users don't always know the best keywords or controlled vocabulary words for their particular academic search, Summon 2.0 would automatically match many common keywords with additional terms that would return results from more technical literature that were relevant for the users search. The example given in the press release is a search for “heart attack.” Summon 2.0 will also return results that match for “myocardial infarction,” the technical term for a heart attack (ProQuest, 2013). Doing a search on GVSU's instance of Summon for “heart attack” also returns the Wikipedia article for “Myocardial Infarction” (Figure 1).
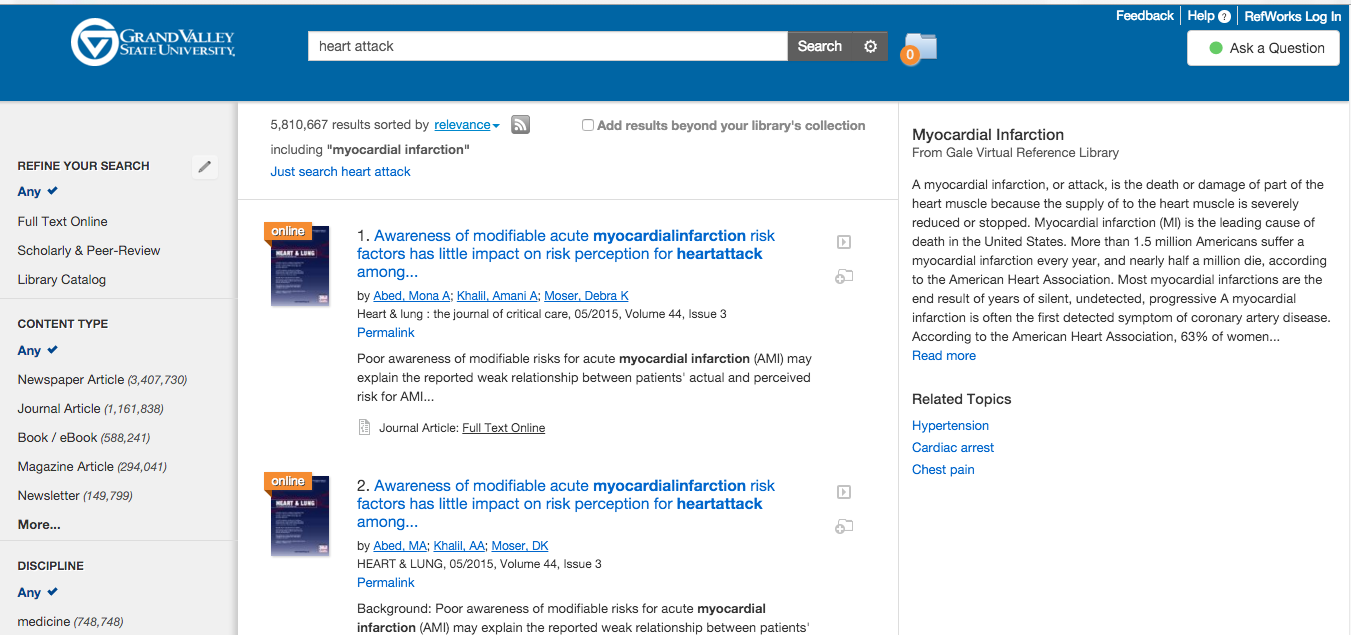
Figure 1
While the exact algorithm that chooses the terms remains a bit of a mystery, Brent Cook (2016), the current Project Manager for Summon, explained a bit behind how the tool works in an email to the Summon Clients list-serv in January 2016:
”We use our log files to identify topics and synonyms for these topics. We index these topic names and synonyms using Solr. We then match the Wikipedia and encyclopedia articles to topics. In the case of Credo, we match through their topic taxonomy, which has links to their encyclopedia articles. Because of this, you will see differences between searches done on the individual platforms as compared to the Topic Explorer in Summon.“
When I first began sketching out tests to measure the effectiveness of algorithms, I was drawn to the one behind the Topic Explorer because it was professing to do something different from all other discovery search results sets. By returning only a single result and placing the result on the right side on wider screens (mirroring Google's Knowledge Graph), the Topic Explorer is meant to say, "this is what you are searching for.” Because there is only a single result, there is a confidence inherent in the design that would make this a test subject for algorithm effectiveness.
What's more, as I was in the planning stages for a project to examine the Topic Explorer, a colleague reminded me of a common search he uses to examine new search tools, “stress in the workplace.” Run in our instance of Summon, the Topic Explorer returned the Wikipedia article for “Women in the workforce (Figure 2). This seemed to be something else worth examining, since rather than just accuracy, this particular result contained what appeared to be gender bias. The result was equating stress at work with working women. I tweeted about the search (Reidsma, 2015), and ProQuest made a change in the algorithm to fix that particular search (ProQuest, 2015). However, I quickly discovered that they had merely blocked the keywords "stress in the workplace” from returning a topic. A search for “stress in the workforce” still returns “women in the workforce,” more than three months after they made their change.

Figure 2
I became interested in testing not just for accuracy in the Topic Explorer, but also for situations where inaccuracy crosses the line into bias. The study of bias in search engine results has a fairly long history. In 2002, Mowshowitz and Kawaguchi emphasized the need for this kind of analysis, since “the role played by retrieval systems as gateways to information coupled with the absence of mechanisms to insure fairness makes bias in such systems an important social issue” (p.143). Indeed, many such studies have looked for anomalies in results. According to Eslami et al. (2015), “researchers have paid particular attention to algorithms when outputs are unexpected or when the risk exists that the algorithm might promote antisocial political, economic, geographic, racial, or other discrimination” (p.154) Indeed, examining problematic results in the Topic Explorer felt like not just a first step in building a toolkit for examining library discovery algorithms, but also of highlighting the moral responsibility we who create technologies for libraries are beholden to. The Topic Explorer itself is designed to change a users’ behavior, to offer “ contextual information to improve research outcomes” (ProQuest, 2013). As Luke Dormehl (2014) reminds us, because technology aims not to describe but to change the world, it is “a discipline that is inextricably tied in with a sense of morality regardless of how much certain individuals might try to deny it” (p.132).
Once I understood the scope of my project, I knew I needed a way to examine a large sample of searches that included Topic Explorer entries. Since not all searches have a Topic Explorer, I couldn't just wade through the ProQuest search logs. Rather, I decided to specifically capture the searches that returned Topic Explorer results. I wanted to know what the search terms were, what topic explorer entry came up, what the entry said, and which provider it was from. Following on Cook’s comment that the Summon Topic Explorer algorithm will return different results in the native tools, I wanted to also examine what results I would have gotten from Wikipedia or Gale Virtual Reference Library if I had searched there directly using the same search terms.
First, I added a small jQuery function to our custom JavaScript file that runs in Summon. The JavaScript looks for Topic Explorer entries on search result pages, and then sends the search terms, the entry title, source, and text to a simple PHP file that saves the data into a MySQL database. I then created a web page that returned and sorted the results. The tool first groups all of the search queries together, counting the number of times the exact same keywords have been used, and then displays the results in chronological order.
I then waited a few months to collect data, and reviewed the first 8,000 search queries that produced a Topic Explorer entry. In most cases, the Topic Explorer showed an entry that matched exactly or very closely the text entered by the user (or, at least the same words, if not in the same order). In one grouping of the page, you'll see a search for “transactional analysis” return a Wikipedia article of the same name, a search for “french revolutionary wars” return the Wikipedia article “French Revolutionary Wars,” and a search for “chinese herbal medicine” return the Wikipedia entry for “Chinese Herbology.” These examples are numerous, and show the benefits of the Topic Explorer algorithm at matching these general searches with relevant reference material.
The algorithm also proved to be quite good at picking up related terms in some cases, regardless of what keywords were entered. At times, this was because of the query expansion, as in the “heart attack” search example. Other times, however, the Topic Explorer algorithm was able to find related entries that were relevant without relying on query expansion. For instance, a search for “ends justify the means” returned the Gale Virtual Reference Library entry for “Consequentialism,” a philosophical outlook in which outcomes are enough to justify actions. Searching the Gale Virtual Reference Library for “ends justify the means” returns over 2,800 results. The first hit is the “New Testament,” and nowhere on the first page of results is “Consequentialism.” Here is a case where Summon's custom indexing has brought a potentially useful reference article out into a user's search.
However, often searches for specific topics were given an overly-generalized reference article, such as a search for “fetal tissue research” which returned the Wikipedia article on “Fetus.” The topic of “fetus” isn't going to be particularly relevant to a search on fetal tissue, especially since the Wikipedia article focuses on fetal development during pregnancy. Searching Wikipedia for “fetal tissue research” returned over 800 results, none of which matched the search directly, either. The majority of the results on the first page were political entries, covering politician or political party positions on fetal tissue research. The ninth result was "Fetus.” In these situations, it seemed that Summon wasn't improving on the native search, but it wasn't hurting things, either.
However, there appeared another group of searches that returned Topic Explorer entries that didn’t match the search terms at all. Of the 8,000 search queries I examined, I flagged 561 as being inaccurate, usually for matching an incorrect Topic Explorer entry with the search. Many of these errors fell into predictable categories, although not all. There were topical searches that returned known item entries, like the search for “skin to skin contact” that returned the Wikipedia page for an Australian pop song called “Skin to Skin.” Often these were subject searches that returned a particular journal, such as the search for “marriage and family” that returns the Wikipedia article on the “Journal of Marriage and Family.” These are at least understandable, if we assume that the algorithm is weighing the keywords in the entry's title more heavily than other factors. More puzzling is the search for “poems” (granted, a terrible search) that returns the Gale Virtual Reference Library's article on Ralph Waldo Emerson. While Emerson was a poet, it hardly seems helpful to introduce the curious user to the entire breadth and history of poetry by offering up a biography of one American writer.
Another group of problems concerned searches for known items. Of these, many returned the wrong known item, usually due to a pattern of words in the titles that was similar. Some examples of this were the searches for “return of the king,” where users expected information on the Tolkien novel but instead were shown the Wikipedia entry for a documentary called “The King of Kong: A Fistful of Quarters.” Searches for the “city of god” (which could either be a topical or known item search) were shown the page about a non-fiction book called “Farm City: The Education of an Urban Farmer.” Many of these known item searches that returned the wrong item concerned journals. Searching for “american journal of transplantation” will get you the “American Journal of Sociology,” and the “journal of aquatic sciences” will offer up the “British Journal of Psychiatry.” No matter how you search, looking for “the prince” or “the prince machiavelli” will get your research on “Prince, 1958-” the “exciting live performer and prolific singer-songwriter,” courtesy of Gale Virtual Reference Library.
Sometimes a topical search returns topical information, but on the wrong topic. While some combinations seem downright nonsensical (“women are homemakers” returns “sociology”), some can be inadvertently humorous, depending on your political or moral leanings. For instance, searching for “united states healthcare system” returns the Wikipedia article on “United States patent law”, which may or may not be a comment on the hold that Big Pharma has on our current healthcare. A search for “princess diana” returns the Gale Virtual Reference Library article on “Wonder Woman.” The search for “creation of patriarchy” perhaps rightly introduces the reader to Michelangelo’s “Creation of Adam” painting, for if there were to be a starting point of the patriarchy, why not at the beginning? A sad commentary on the rising cost of college tuition might be the search for “united states egg price” which gives us Wikipedia's entry on “Student financial aid in the United States.” Those concerned with the influence of sports in our culture will no doubt be pleased to see a search for the “culture of sports” return “the culture of narcissism,” and it does seem appropriate to learn more about “legal drugs in the united states” by studying “Public holidays in the United States.” Perhaps my favorite, “branding” returns “BDSM,” the Wikipedia article for Bondage, Discipline, Sadism, Masocicism dealing with fantasy role play. It's hard not to read that as a statement about corporate image creation.
While the sample of incorrect Topic Explorer associations I shared above might be read as sly commentary on our political or educational systems, other results in the Topic Explorer presented a darker perspective. This is not uncommon when dealing with algorithms. Mike Ananny (2011), writing in The Atlantic, told of installing Grindr, a location-based dating and socializing app for gay men, and looking at the algorithmically generated “related” apps. Included was a “Sex Offender Search” app. In teasing out how the algorithm decided that gay men and sex offenders were topically related, he notes that “reckless associations—made by humans or computers—can do very real harm especially when they appear in supposedly neutral environments.”
In 2013, Harvard professor Latanya Sweeney published an article that argued that searching for “racially associated” names on Google and other services had a significant effect on whether an advertisement implying that the person you were searching for had been arrested. “Black-identifying names” like DeShawn and Trevon were 25% more likely to be shown an ad suggesting that the person had been arrested than names associated with whites, like Jill or Emma. These results are not connected to whether the names actually have an arrest record, but seem to be algorithmically biased.
Of the 561 Summon queries I judged as returning incorrect Topic Explorer results, I flagged 54 as displaying potential for bias (including the BDSM entry I just mentioned). That is 9.63% of the problematic search queries, or .68% of the 8,000 I reviewed.
Mowshowitz and Kawaguchi proposed two kinds of bias that can come from matching algorithms. The first is “indexical bias,” where bias is evident in the selection of items. “Content bias,” however, comes from the content of what was selected (2012, p.143). Of the 54 potentially biased results, the majority were instances of “indexical” bias, where the matched subject term was enough to imply bias in the matching algorithm.
Indexical bias most often occurred where a search query was matched with an article that implied a social, moral, or political comment on the original search terms. For instance, a search for “corrupt government in united states” returned the Wikipedia entry for “Government procurement in the United States,” making the implication that the Government's supply chain is inherently corrupt. Another example was a search for “pollution levels in the usa” which offered the user the Gale Virtual Reference Library article on “Education in the United States.” Say what you will, we've had vigorous debates about education in America, but I don't think it's quite reached the point where we can classify it as smog.
Bias cut the other way, at times, such as a search for “history of human trafficking” that returned Wikipedia's entry for the “History of human sexuality,” an entry that may be related to trafficking but by no means subsumes the entire topic.
This isn't to say that bias was put into the algorithm intentionally. However, the end result is the same, regardless of intent. The important thing is to understand how the results were mapped to specific search terms and address the problem.
The majority of the 54 biased search results were related to women, the LGBT community, race, Islam, and mental illness. I’ve reproduced each of these categories below, including any spelling errors present in the original search queries.
Biased Results About Women
| Search terms | Topic Explorer Result |
|---|---|
| women in the holocaust | Women in the military |
| stress in the workforce stress in the workplace |
Women in the workforce |
| women in the middle east | Women in the Middle Ages |
| rape in united states | Hearsay in United States law |
| women roles in household | Gender roles in Christianity |
| virginity | Sexual abstinence |
| history of women's rights | History of far-right movements in France |
| indulgences in the middle ages | Women in the Middle Ages |
| women in the governement [sic] | Women in the military |
| the birth of feminism | The Birth of Tragedy |
| corruption in the army | Women in the military |
| united states rape culture | Culture of the United States |
By far, the most problems encountered were related to gender. Here we see the comparison that started my examination of the Topic Explorer, the result that says “women” are the same as “stress” when found in the workplace. Perhaps one of the most offensive entries suggests that researchers looking into “rape in united states” have a look over the Wikipedia article on “Hearsay in United States law,” which describes unverified statements made about an event while not under oath (Figure 3). Implying that a search for information on rape in this country is tantamount to searching for unverifiable claims goes beyond merely being incorrect, it's offensive. A search through the text of the Wikipedia entry on Hearsay shows that the word “rape” never appears in the text.

Figure 3
Another topic is a bit perplexing since they seem to reflect one side of contemporary moral debates: a search for “virginity” that produces the entry for “Sexual abstinence” implies a certain moral or political stance, these days. Especially since Wikipedia has a perfectly useful entry on Virginity. (The word virginity only appears on the Sexual abstinence page three times, and two of those are in see also references. In contrast, it appears 121 times in the Virginity entry, including in the title.) Of course, the Summon results page indicates that they have expanded the default search of virginity to include “sexual abstinence.” Removing that query expansion will return the Wikipedia “Virginity” entry. While query expansion works well in the case of using synonyms, this query expansion is a different matter. One can be sexually abstinent without being a virgin, and so including the query expansion makes the Topic Explorer entry look like a synonym for virginity.
At least a biased result you'd get when searching for “the birth of feminism” has some technical explanation: when you're shown “The Birth of Tragedy,” hopefully you'll understand that the algorithm was matching a pattern of words, not comparing feminism with tragedy. Likewise, the “corruption in the army” search that returns the entry on “Women in the military” is matching a pattern in the title and using a synonym: you can try this experiment yourself by putting whatever you like in place of the “x” when visiting GVSU's Summon: “X in the military” will almost always return the Wikipedia entry for “Women in the military,” as if the Topic Explorer has become a sort of Mad-Libs. The same pattern is at work with many searches for "women in the,” as evidenced by the suggestion that the only role for women in the government is in the military. Matching “history of women's rights” with French far-right movements it latching on to the indexical term “right,” although missing the different context and meaning, and implying that women’s rights are a form of extremism. The word “women” never appears in the entry on French's far-right movements, indicating that the algorithm is overemphasizing the keyword matching in the title.
Another pattern matching error that appears biased is the suggestion that like “indulgences in the middle ages,” women during that time were tools to be handed out by the church to reduce the time someone spent in purgatory. As for the “stress in the workplace” search that ProQuest fixed, you can still find the biased result by switching to workforce. Nearly any noun can be added to a search “X in the workforce” and you'll still get the entry about women.
Biased Results About the LGBT Community
| Search terms | Topic Explorer Result |
|---|---|
| domestic violence in the united states | Domestic partnership in the United States |
| lesbian literature | Lesbian fiction |
| crimes of the community | Healthcare and the LGBT community |
Here we have domestic violence equated with domestic partnership (Figure 4). While both of these subjects apply to both hetero- and homosexual relationships, domestic partnership began as a way to recognize same-sex unions. With the amount of controversy surrounding sax-sex marriage in the United States, this kind of “reckless associations” can add fuel to an already contentious debate.

Figure 4
Another match implied either that the only literature available for or about lesbians is fiction. When searching for “lesbian literature,” the Topic Explorer shows an entry for “lesbian fiction,” as well as the “Related topics” of “science fiction” and “speculative fiction.” This likely stems from a decontextualized association between the term literature and the term fiction. However, a search for “gay literature” in Summon returns the Wikipedia article “Gay Literature,” and Wikipedia has an entry entitled “Lesbian literature.” Even more perplexing is the fact that the Wikipedia entry for “Lesbian fiction” was redirected to the more broad entry “lesbian literature” in October 2015. I am writing this four months later, and the Wikipedia entry in Summon’s index still has not been updated.
The final match in this category equates “crimes in the community” with “Healthcare and the LGBT community.” Implying that providing healthcare to a particular population is a crime, especially a community that already suffers from overt prejudice and discrimination, is not a stance that libraries want to be associated with.
One other topic was initially flagged, although on investigation I decided to remove it from the examination. Searching for “lgbt youth” in Summon will return the Wikipedia entry on “Suicide among LGBT youth.” There is no Wikipedia entry for “lgbt youth,” and in fact a search on Wikipedia for that topic returns the entry for “Homelessness among LGBT youth in the United States” and “Suicide among LGBT youth” as the first two results. This is an instance where the algorithm seems to be zeroing in on an entry that includes the search keywords frequently, because sadly, much of the discussion around LGBT youth today centers around suicide and homelessness.
Biased Results About Islam
| Search terms | Topic Explorer Result |
|---|---|
| muslim terrorist in the united states | Islam in the United States |
| islamic day of judgment | List of modern-day Muslim scholars of Islam |
In searches about Islam that returned a Topic Explorer result, Summon did consistently well. This is largely due to a number of topic-specific Wikipedia articles on different aspects of Islam, ranging from articles on Islam’s historical roots, its importance to the intellectual development of Medieval Europe, as well as the religion’s more contemporary roles in the West and relationship with extremist groups.
However, some searches were clearly problematic, especially searching for “muslim terrorist in the united states,” which returned a Wikipedia article on the religion itself. Matching a search for information about terrorists with the entire religion only adds to the stereotypes perpetuated in the aftermath of terrorist attacks in Paris and California. This is especially problematic given that Wikipedia itself has an entire entry on Islamic Terrorism (there is also a Christian Terrorism entry). Why not bring up the page specifically about terrorism related to that particular religion? The word “terrorist” only appears once in the Islam article, while it appears almost a hundred times in the Islamic Terrorism article. Even “united states” appears 24 times in the Islamic Terrorism entry, while only appearing 5 times in the article on Islam the religion.
What’s more, returning a list of individuals for a search on the “islamic day of judgment” is perplexing. No where in the article does the word “judgment” appear, and except for its appearance after “modern” in the title, the word “day” is absent as well. If someone was concerned with the Islamic “day of judgment,” what would they do about a list of individuals who are identified as muslims?
Searches for “muslim schools in the us” or “islamic schools in the us” return the general entry for “Education in the United States,” perhaps suggesting to some that all schools in the United States are muslim. But this is again an example of naive pattern matching, it seems. Like the earlier Mad Libs searches, you can enter nearly any noun you like into the pattern “X schools in the US” and get this result. This would seem to be more evidence for the additional weight of the title of the topic entry.
Biased Results About Race
| Search terms | Topic Explorer Result |
|---|---|
| white slavery | Moral panic |
| the black woman | The Woman in Black |
| early childhood development policies in south africa | Apartheid in South Africa |
| forced marriage united states | Desegregation busing in the United States |
| race in the media crime definition in the united states race in the world teaching about race |
Race and crime in the United States |
| history of poverty in america | History of slavery |
If you search in Summon for “white slavery,” the Topic Explorer will present you with a Wikipedia entry for “Moral Panic.” (Figure 5) Searching for “black slavery,” meanwhile, returns a blank topic explorer pane, perhaps because Wikipedia itself will offer you nearly 10,000 possible entries related to black slavery. But why is white slavery related to moral panic, while black slavery is not? It’s true that the Moral Panic article uses the phrase twice (although one of those is in the references), but Wikipedia itself also has a perfectly suitable entry on “White Slavery.” How could the algorithm make this kind of a judgment about a topic?

Figure 5
Most of the results so far have concerned indexical bias, but there are times when Topic Explorer results show both indexical as well as content bias. Searching for “the black woman,” a user will be presented with a Wikipedia entry for The Woman in Black, a horror film from the early 1980s. Strangely, Summon’s autocomplete algorithm seems to recognize that this search is probably a known-item search for The Black Woman: An Anthology, but the algorithm for autocomplete must not share what it has learned with the Topic Explorer. The content of the Wikipedia article describing the film, however, suggests that what you are looking for is a “menacing spectre that haunts a small English town.” Of course, what is throwing off the search is the addition of the definite article (common in known item searches). A search in Summon for “black woman” brings up the Wikipedia entry on “Black people,” which is redirected from the “Black woman” entry.
Making associations between business practices or child rearing techniques and Apartheid, the institutionalized segregation in South Africa that lasted until the mid-1990s is morally problematic. Likely this is because the algorithm again latches on to a pattern of words, including “in south africa” and uses the apartheid article as a go-to result. In fact, nearly any noun you add to the phrase “X in south africa” will return this result. From “freedom” to “snow” to “soccer,” nearly any search seems to imply to the algorithm, “you must be interested in apartheid.”
Further associations are to equate forced marriage in the US with the desegregation of busing during the Civil Rights movement. Since “marriage” doesn’t appear anywhere in the busing article, I’m unsure of what to make of this connection. The title of the article used in Summon was actually redirected to the “Desegregation busing” entry in January of 2013, which was before Summon 2.0 launched to the public, which presents another question: how often are these entries updated?
Many searches that involve crime or race on their own will show Wikipedia’s entry on “Race and crime in the United States.” I’ve shown the selection of four such searches from the 8,000 entries I examined. In the case of a search for a definition of “crime,” I’m especially perplexed as to why the Topic Explorer would choose the Race and Crime entry, since Wikipedia’s entry “Crime” contains the word “definition” 14 times (although some of those are in use of conceding that it is hard to agree on a consistent definition). But why bring race into question if the user only asked about crime? And why also bring crime into the conversation if the user is asking about race alone? The Wikipedia entry on Race (human categorization) contains a total of six uses of the word crime, although four of them are in “See also” notes. (Race (biology) has no mentions of crime.) This seems to be a case where the algorithm is suggesting possible cross-disciplinary connections, but it does so in a way that amplifies stereotypes. The same can be said of suggesting that poverty is a result of slavery, which is heavily tied up with race. Are we to assume that poor people are still slaves, or that only those whose lineage included being enslaved are poor? The connection is not helpful from a research standpoint, and so we are left trying to make moral or political associations between the topics.
What’s more, searching for items of importance to Africa, the continent, tend to default to topics about African-americans. For instance, “african history” and “african culture” both return articles about African-American history and culture. This isn’t dependent on GVSU being an American university, either. The result also appears at the University of Huddersfield in the UK as well as the National University of Singapore, both of which use Wikipedia as a Topic Explorer source1. This effectively implies that Africa itself doesn’t have a history or culture of its own. Wikipedia has a perfectly serviceable article on “History of Africa” and “Culture of Africa”, each of which can be found by searching Wikipedia natively with the same keywords as the Summon search.
Biased Results About Mental Illness
| Search terms | Topic Explorer Result |
|---|---|
| mental illness stigmas of mental illness the stigma of mental illness the suffering of illness signs of mental illness symptoms of mental illness |
The Myth of Mental Illness |

Figure 6
Nearly every search I’ve conducted in Summon that includes the words “of Mental Illness” shows me the Wikipedia entry for a controversial book by the psychiatrist Thomas Szasz entitled The Myth of Mental Illness. Szasz’s argument was one with the way that psychiatry and psychoanalysis were being conducted in the mid-twentieth century, but the title of his book was not intended to suggest that mental illness does not exist. Yet Summon consistently returns this strongly suggestive result whenever users search for topics related to mental illness. Wikipedia itself has a very long and in-depth entry on Mental Disorder, redirected from Mental Illness, which even includes a sentence about the role Szasz played in the development of the legal and psychological understanding of mental illness in the twentieth-century. Yet none of this is presented to our Summon users. Rather, any search for mental illness (or, in some cases, just “illness”) gives a headline that suggests that the topic they are studying is nothing more than a myth.
Next steps
Since the goal of the Topic Explorer is to identify the underlying topic behind a user's search, incorrect or biases results can have a great impact on a user's perception of a topic. By showing results that exploit stereotypes or bias, the Topic Explorer is saying to the user, “this is what you are looking for.” The purpose of my examination was to bring these anomalies to light and start a discussion within the library community about how to improve our search tools for everyone.

Figure 7
After examining the data, I took several steps to improve Summon’s Topic Explorer for my users. First, I made some modifications to the user interface of the Topic Explorer to give users the ability to report incorrect or biased Topic Explorer results, as well as offering some contextual information on how the Topic Explorer result was chosen (Figure 7). Second, I shared the analyzed data with ProQuest’s Summon team, so that they had data on search queries done by users and the Topic Explorer results that were returned. These two steps were meant to address the results that were either incorrect or biased. By sharing the analyzed data with ProQuest, I hoped that the algorithm could be improved so that biased results would be less common. And by offering contextual information about the Topic Explorer as well as a button to report a problem, I hoped to not only encourage reports but also to remind our users that these tools are not oracles, and the truths they claim can and should be questioned.
The third change I have proposed was more of a byproduct of the analysis. When Summon first launched, we left the default Topic Explorer sources in place: Wikipedia and Gale Virtual Reference Library. When the Topic Explorer was first launched, much of the discussion on the Summon list-serv was about the “reliability” of the reference sources. Wikipedia was scorned as a useful source, and some academic libraries still only provide Topic Explorer results from subscription reference sources like Credo and Gale Virtual Reference Library.
While analyzing the data, I discovered something that I wouldn’t have suspected before wading into the details of how the Topic Explorer works. Because the Topic Explorer attempts to give a quick and dirty summary of a topic rather than a lengthy treatise. Since Wikipedia has a style guide that requires authors to start their entries with a short summary, Wikipedia entries are perfectly suitable to being broken up and shown in bits and pieces. Gale Virtual Reference Library, however, was a more typical encyclopedic style that assumed the reader would take in the entire article at once. When Summon pulled out the lead paragraph of a Gale Virtual Reference article, then, it often seemed out of place with the search terms and the Topic Explorer heading.
For instance, a search for “curiosity in children” in Summon returns the Gale Virtual Reference Library entry on “Parenting styles,” which begins:
The study of human development is centrally concerned with understanding the processes that lead adults to function adequately within their cultures. These skills include an understanding of and adherence to the moral standards, conventional rules, and customs of the society. They also include maintaining close relationships with others, developing the skills to work productively, and becoming self-reliant and able to function independently. All of these may be important to successfully rear the next generation.
This paragraph hardly gives a summary of either children’s curiosity or parenting styles! Searching for the “freedom of religion act”returned a Gale article on “Freedom of Religion,” which begins, “The most authoritative statement of Catholic teaching on religious freedom is the Declaratio de Libertate Religiosa of VATICAN COUNCIL II” before wandering off in a description of Vatican II’s role in changing the face of the Catholic Church in the twentieth century2. I’m not sure that helps a novice researcher looking for information on the US Government’s 1993 Religious Freedom Restoration Act, which, incidentally, Wikipedia has a terrific entry on.
In addition, because GVSU doesn’t subscribe directly to Gale Virtual Reference Library, we found that our access to the materials didn’t always give our users the most up-to-date information. We get most of our GVRL content from the Michigan eLibrary, which purchased content in 2005 but hasn’t updated the content since. As a result, the entry shown for a search on Osama bin Laden details his life up until 2005, but includes nothing of the later developments in the War on Terror or in his assassination in 2011.
I've presented my findings to our electronic resources and collection development librarians, and hope they will agree to switch from Gale Virtual Reference Library to Credo Reference as our second source, since it lends itself to breaking out summary articles and we have a current subscription, allowing us access to up-to-date content.
The Topic Explorer was a good first step in analyzing discovery algorithms, since it's message was different than the rest of our search results. Moving forward, I hope that ProQuest will take steps to improve the algorithm that matches search results to Topic Explorer entries, while I continue to examine these “black box” algorithms for accuracy and, most importantly, bias.
Thank you to Annette Bailey, Hazel McClure, Kyle Felker, and Patrick Roth for conversations and suggestions while I worked on this project. Thanks also to Brent Cook of ProQuest for taking he research seriously, and bringing the results to the development team.
Notes
- Of course, it’s possible that Summon is checking my IP address when doing a search and localizing. This would be common with a Google search, but I wouldn’t think it would be a good feature for a library discovery platform, since students and researchers may be living or traveling abroad, and their current location does not change the nature of the research needs. ↩
- It also seems that Summon’s tool for scraping the content from Gale ignores font italics or all caps, so the actual entry shown in the Topic Explorer reads: “The most authoritative statement of Catholic teaching on religious freedom is the of .” ↩
References
Ananny, M. (2001). The curious connection between apps for gay men and sex offenders. The Atlantic, April 14. Retrieved from http://www.theatlantic.com/technology/archive/2011/04/the-curious-connection-between-apps-for-gay-men-and-sex-offenders/237340/
Bogost, I. (2015). The cathedral of computation. The Atlantic. Retrieved from http://www.theatlantic.com/technology/archive/2015/01/the-cathedral-of-computation/384300/
Cook, B. (2016, January 11). [summonclients] RE: Topic Explorer algorithm. [Electronic mailing list message]. Retrieved from http://mail.lists.summon.serialssolutions.com/sympa/arc/summonclients/2016-01/msg00014.html
Dormehl, L. (2014). The formula : how algorithms solve all our problems—and create more. New York: Penguin.
Ekström, A. (2015, January). Andreas Ekström: The moral bias behind your search results. [Video file]. Retrieved from https://www.ted.com/talks/andreas_ekstrom_the_moral_bias_behind_your_search_results
Eslami, M., Rickman, A., Vaccaro, K., Aleyasen, A., Vuong, A., Karahalios, K., Hamilton, K., & Sandvig, C.. (2015). “I always assumed that I wasn’t really that close to [her]”: Reasoning about Invisible Algorithms in News Feeds. 33rd Annual ACM Conference on Human Factors in Computing Systems. pp. 153-162. Retrieved from http://www-personal.umich.edu/~csandvig/research/Eslami_Algorithms_CHI15.pdf
Gillespie, T. (2012). Can an algorithm be wrong? Limn, 1(2). Retrieved from http://limn.it/can-an-algorithm-be-wrong/
Gillespie, T. (2014). The Relevance of Algorithms. In T. Gillespie, P. Boczkowski & K. Foot (Eds.), Media Technologies: Essays on Communication, Materiality, and Society.(pp. 167-194). Cambridge, MA: MIT Press.
Introna, L., and Nissenbaum, H. (2000). Shaping the Web: Why the politics of search engines matters. The Information Society, 16(3). pp. 169-185. Retrieved from http://www.nyu.edu/projects/nissenbaum/papers/ShapingTheWeb.pdf
Latour, B. (1987). Science in action: how to follow scientists and engineers through society. Cambridge, MA: Harvard University Press.
Mowshowitz, A., & Kawaguchi, A. (2002). Assessing bias in search engines. Information Processing and Management, 38(1). pp. 141-156.
Noble, S. (2012). Missed connections: What search engines say about women. Bitch, 1(54). pp. 36-41. Retrieved from https://safiyaunoble.files.wordpress.com/2012/03/54_search_engines.pdf
ProQuest. (2013). Serials Solutions Advances Library Discovery with Summon 2.0. Retrieved from http://www.proquest.com/about/news/2013/Serials-Solutions-Advances-Library-Discovery-with-Summon-2-0.html
ProQuest. (2015, November 11). @mreidsma We are working to address the issue with the Wikipedia articles.. [Tweet]. Retrieved from https://twitter.com/ProQuest/status/664561101904965633
Reidsma, M. (2015, November 11). Then I looked in Summon at a common search, and saw the sidebar: http://gvsu.summon.serialssolutions.com/#!/search?ho=t&l=en&q=stress%20in%20the%20workplace … @safiyanobel 3/3. [Tweet]. Retrieved from https://twitter.com/mreidsma/status/664508446054699008
Sherratt, T. (2016). Seams and edges: Dreams of aggregation, access & discovery in a broken world. Retrieved from http://discontents.com.au/seams-and-edges-dreams-of-aggregation-access-discovery-in-a-broken-world/
Steiner, C. (2012). Automate this: How algorithms came to rule our world. New York: Portfolio/Penguin.
Terkle, S. (1997). Life on the screen: Identity in the age of the Internet. New York: Simon & Schuster.
Vaidhyanathan, S. (2011). The googlization of everything (and why we should worry). Berkeley: University of California Press.
Edited 1/24/2017 to remove links to web page showing all results, as this tool was removed from the GVSU Libraries server. Analyzed results are still available at http://dx.doi.org/10.5281/zenodo.47723.