Auditing Algorithms
in Commercial Discovery Services
On February 15, 2018, I gave a talk at Code4Lib conference in Washington, D.C. This is an adaptation of my talk. You can also view my slides, or watch a recording of the talk.
Many library folks have a go-to search they use to try out different search tools. By using the same terms in many tools over a period of time, you can get a good sense of how a search tool's algorithms perform in comparison to other tools you've tried. I use "batman," because it's short, and the search results will be a mix of popular and scholarly sources, a variety of formats, and items from the 16th and 17th centuries. This itself is a crude but simple way to evaluate algorithms, but it is ruled more by gut and memory than analysis.
This
Is
My
Search
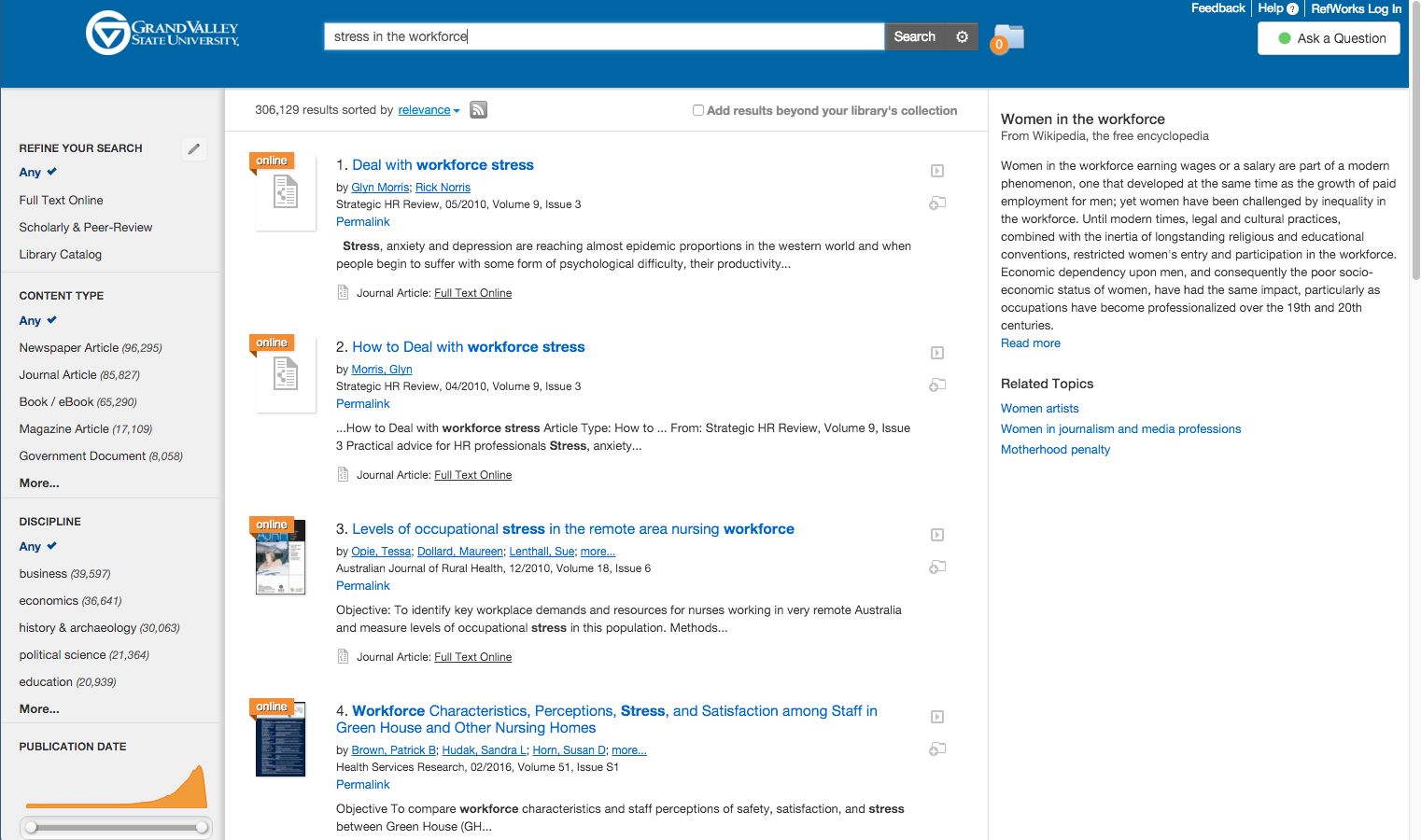
In 2015 my colleague Jeffrey Daniels showed me the Summon search results for his go-to search: "Stress in the workplace." Jeff likes this search because 'stress' is a common engineering term as well as one common to psychology and the social sciences. The search demonstrates how well a system handles word proximities, and in this regard, Summon did well. There are no apparent results for evaluating bridge design. But Summon's Topic Explorer, the right-hand sidebar that provides contextual information about the topic you are searching for, had an issue. It suggested that Jeff's search for "stress in the workplace" was really a search about women in the workforce. Implying that stress at work was caused, perhaps, by women.
I shared it with the Summon team, and within a day they blocked the result.
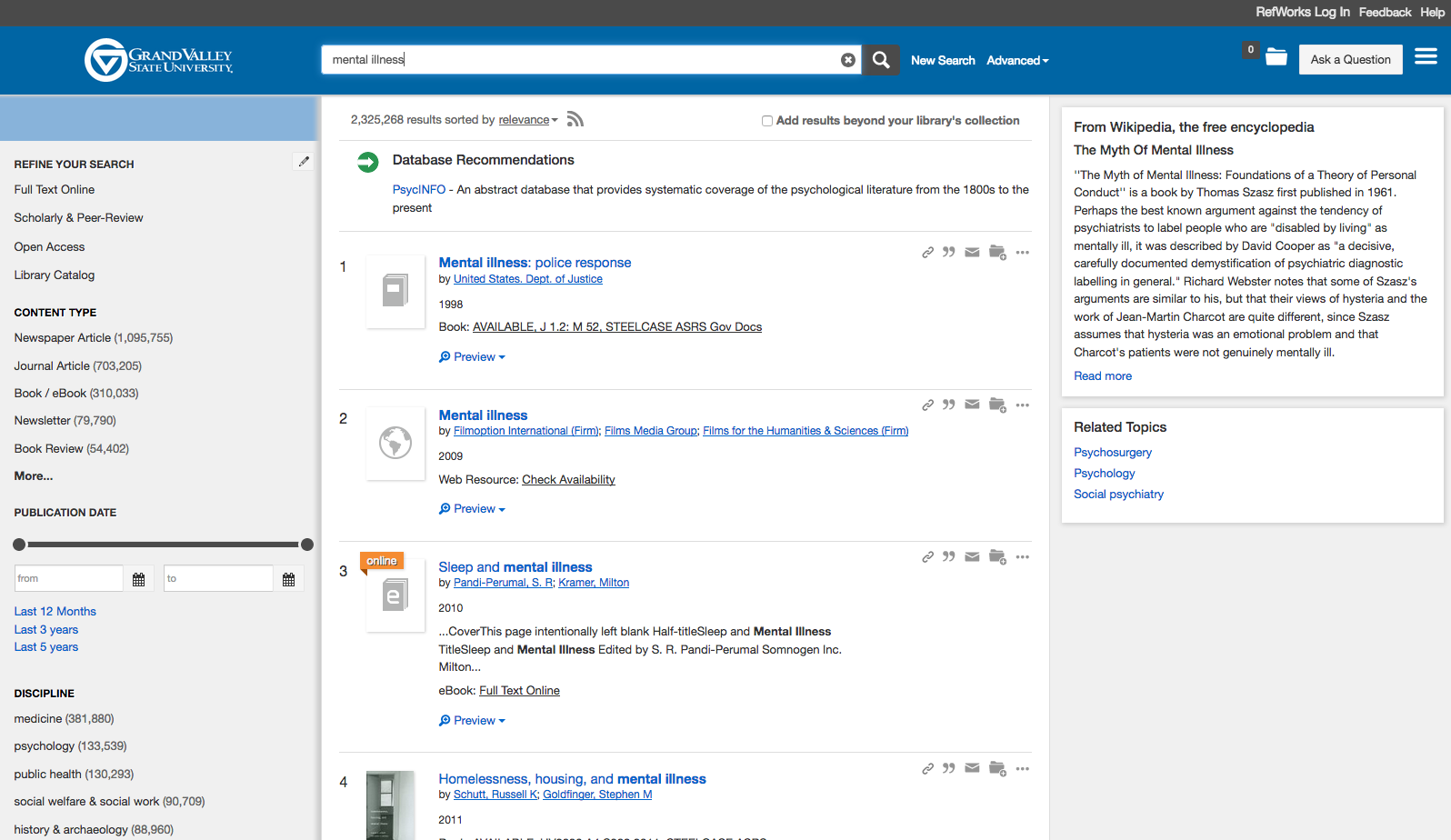
I started looking closer at the Topic Explorer, eventually combing through 8,000 searches that returned a Topic Explorer result and found a number of other problems, mostly in searches related to women, the LGBTQ community, African Americans, Muslims, and mental illness. I shared my results with the Summon team, and they "blocked" many of the problematic results, although not this one, or any search related to mental illness, which still suggests it is a "myth."
It's important to note that they did not adjust the Topic Explorer algorithm. Instead, they hid "problematic" results. In my conversations, I came to realize that they saw this as a technical problem, not a social or moral one.
Technology is a branch of moral philosophy, not of science.
– Paul Goodman
It reminded me of Paul Goodman's quip in the late 1960s about how technology is primarily an ethical undertaking. Goodman's point was that all our decisions about how people live and work and act in the world are fundamentally moral issues. But the growing body of research on critical algorithmic studies confirms that most if not all companies that produce algorithmic systems see them (or at least publicly claim to see them) as neutral, objective technical achievements. The footer of Google News, for instance, reminds us that the stories were "selected by an algorithm," and not by people, as if that absolves the company of any editorial issues.
If we see biased results as a technical problem, an acceptable solution may be to hide the offending results. But solutions that make sense for technical issues will often be different from solutions that make sense for ethical issues.
System design reflects the designer's values and the cultural context.
– Andreas Orphanides
Last year, Code4Lib's own Andreas Orphanides pushed back against the idea that these systems are objective, neutral and exclusively technical. When I began researching library discovery algorithms, I began by reading a lot of critical studies of algorithms, which mostly focus on public, commercial systems that use algorithms: Google, Facebook, Twitter, policing and legal software. Very important work is bring done by an incredible community of journalists and scholars like Julia Angwin at Propublica, Zeynep Tufekci at the University of North Carolina, and Safiya Noble at the Annenberg School of Communication, whose new book Algorithms of Oppression comes out February 20th. (You should buy it, and get your library to buy it, too.)
While a lot of academics focus on algorithms outside the academy, I was interested in the algorithms within Higher Ed that condition the learning environment.
A basic definition of an algorithm is a set of steps used to process an input to produce an output. So, to begin to audit an algorithm, we might want to know the steps the algorithm walks through, either in code or in pseudo-code. What decisions are being made? But here's the catch: all of the commercial discovery tools consider their search algorithms to be major intellectual property assets. They won't reveal the code or even pseudo-code to us.
Of course, algorithms are hardly straightforward and linear, and it's unlikely we would be able to make heads or tails out of the code if we had access to it. And the steps built out of code are only part of the story: the index has to be considered, too. What the algorithm looks for only makes sense if you understand what it looks at. We don't even know the exact parameters of what is in the discovery service's index (although there is more clarity here, since the index is what shows up as visible outputs.)
So, we look for hints, or proxies for the algorithm. I started by looking through Summon's administrative settings. Any setting that allowed me to change how results appear or are ranked gave a hint to something the algorithm values. The Summon documentation was also helpful. Articles explained what fields were searched, how records were de-duplicated, how the algorithm determines "relevance" (in very general terms), and how to conduct advanced search techniques such as keyword weighting and proximity searches. Taken together, these helped me better understand how the algorithm and the index work together. I also read through mailing list posts from the project managers, specifically around changes to or the functioning of the algorithm, and read the release announcements carefully.
But looking at code or understanding the boundaries of the index will only get you so far, and risks fetishizing the algorithm. Algorithms exist to do something, to create outputs from inputs. We need to see them work.
So, while the inner workings are still hidden, we can see what kinds of outputs we get by changing inputs.
But typing in searches one at a time doesn't scale.
So I captured the results as our users searched in Summon. This has the benefit of showing actual searches rather than hypothetical searches.
Whenever Summon executed a search and a Topic Explorer result was shown, my script would grab the search query and the heading, source, and text of the Topic Explorer result and send a POST request to a PHP script that parsed the data and stored it in a MySQL database. This method works for looking at the results of what other people are searching for, but you need to be cautious about privacy. In this case, searches that bring up Topic Explorer results are very general searches, often 1-2 terms. By not saving any information about who did the search, what other searches they did, or when the search was run, I lowered the possibility of capturing reidentifiable data about our users.
You could easily convert this to a bookmarklet to run on a page where you define a search, or create a bot or spider to scrape the page and store the results from all manner of algorithms: search results, database recommendations, spelling corrections, query expansions, autosuggestions, related topics, related searches, and more. (There are some legal concerns we'll get to in a moment with these approaches.)
I matched 8,000 search queries with their respective topic explorer results, and released them as a data set, if you want to look them over or use them in your research. The data set includes very general search terms and the respective Topic Explorer result for each.
8,000 results is a lot of results when you are reviewing them one at a time by yourself. But to understand the workings of a complex algorithm? It's not nearly enough. But it's a start.
I shared my data set with the Summon team in advance of publishing my results, which looked at the set of 8,000 results and found that the Topic Explorer algorithm was able to at least generally identify a topic about 90% of the time.
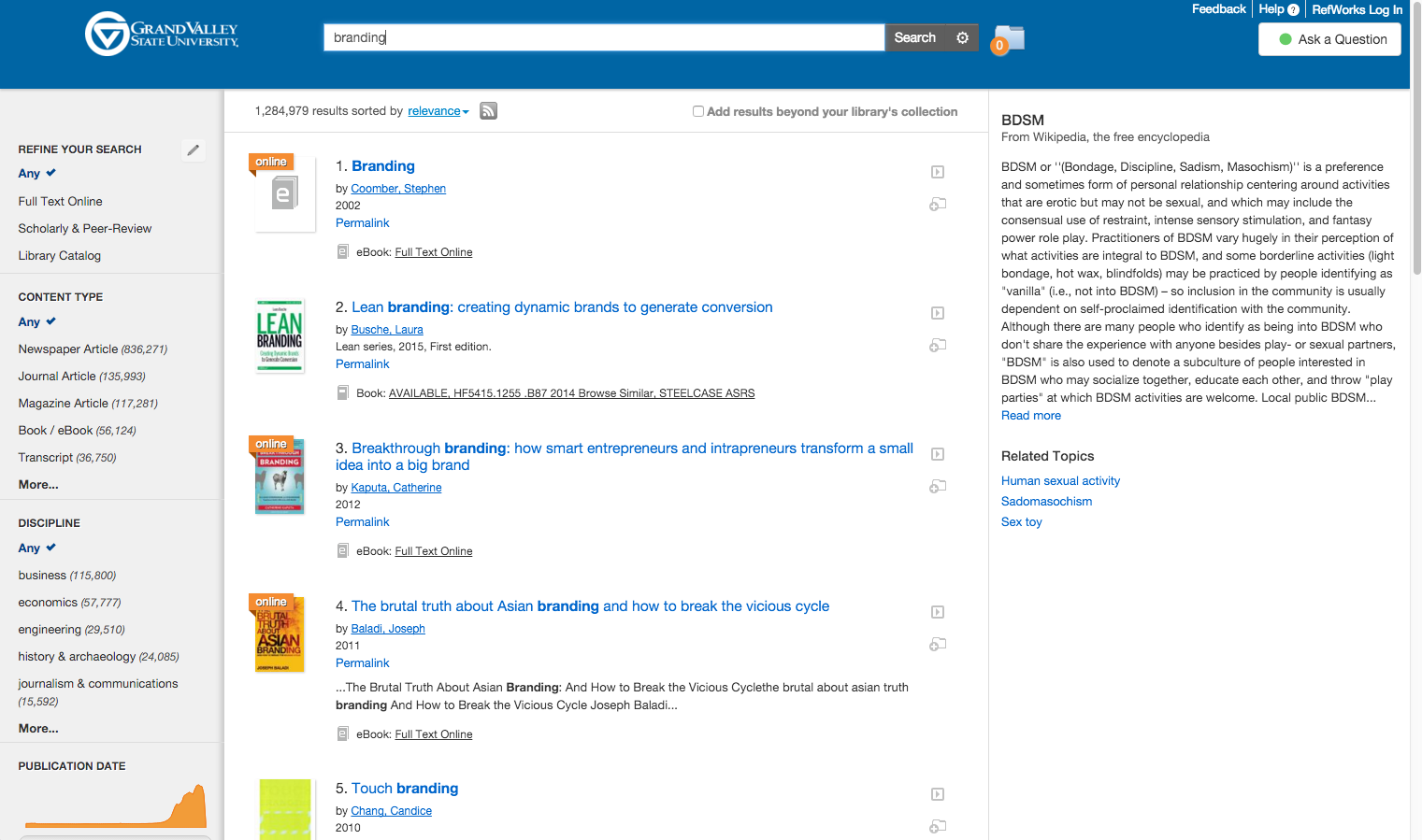
About 1% of the results were biased. The remaining 9% were incorrect, but maybe not all wrong, like this search that equated the ubiquitous marketing concept of "branding" with Bondage, Discipline, Sadism, and Masochism.
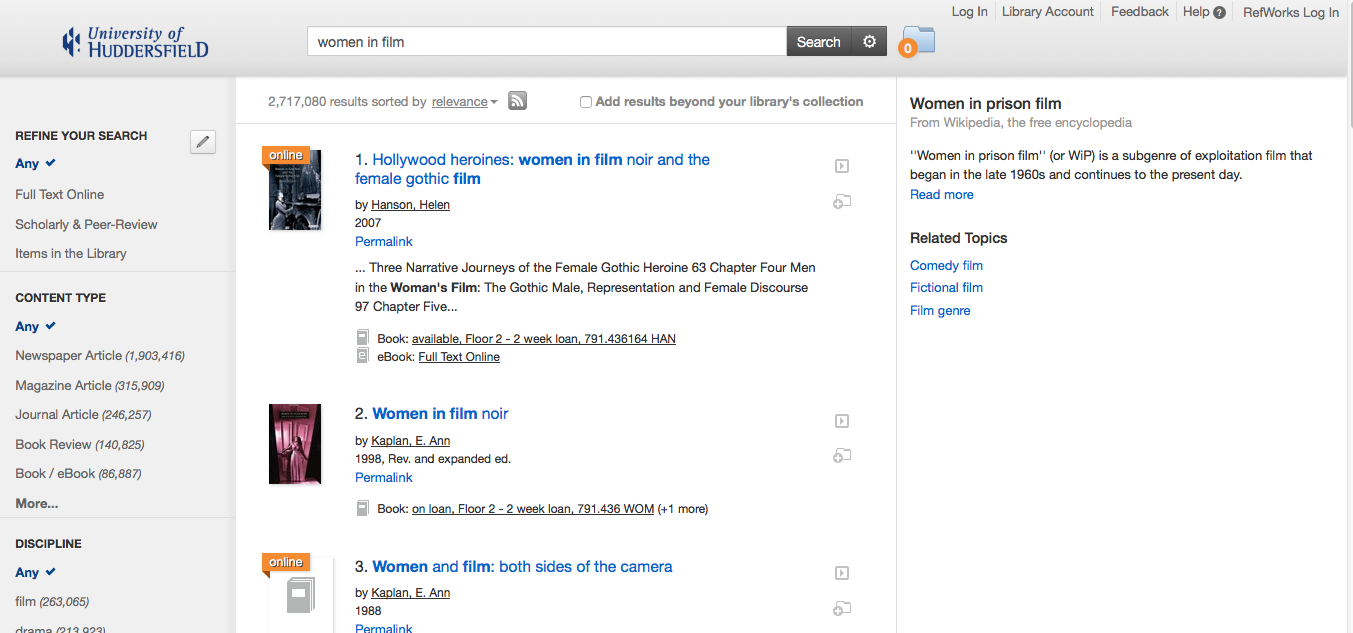
But often the incorrect results slipped into bias, reinforcing negative stereotypes, like a search for "women in film" that apparently couldn't imagine anything more relevant than an exploitation genre.
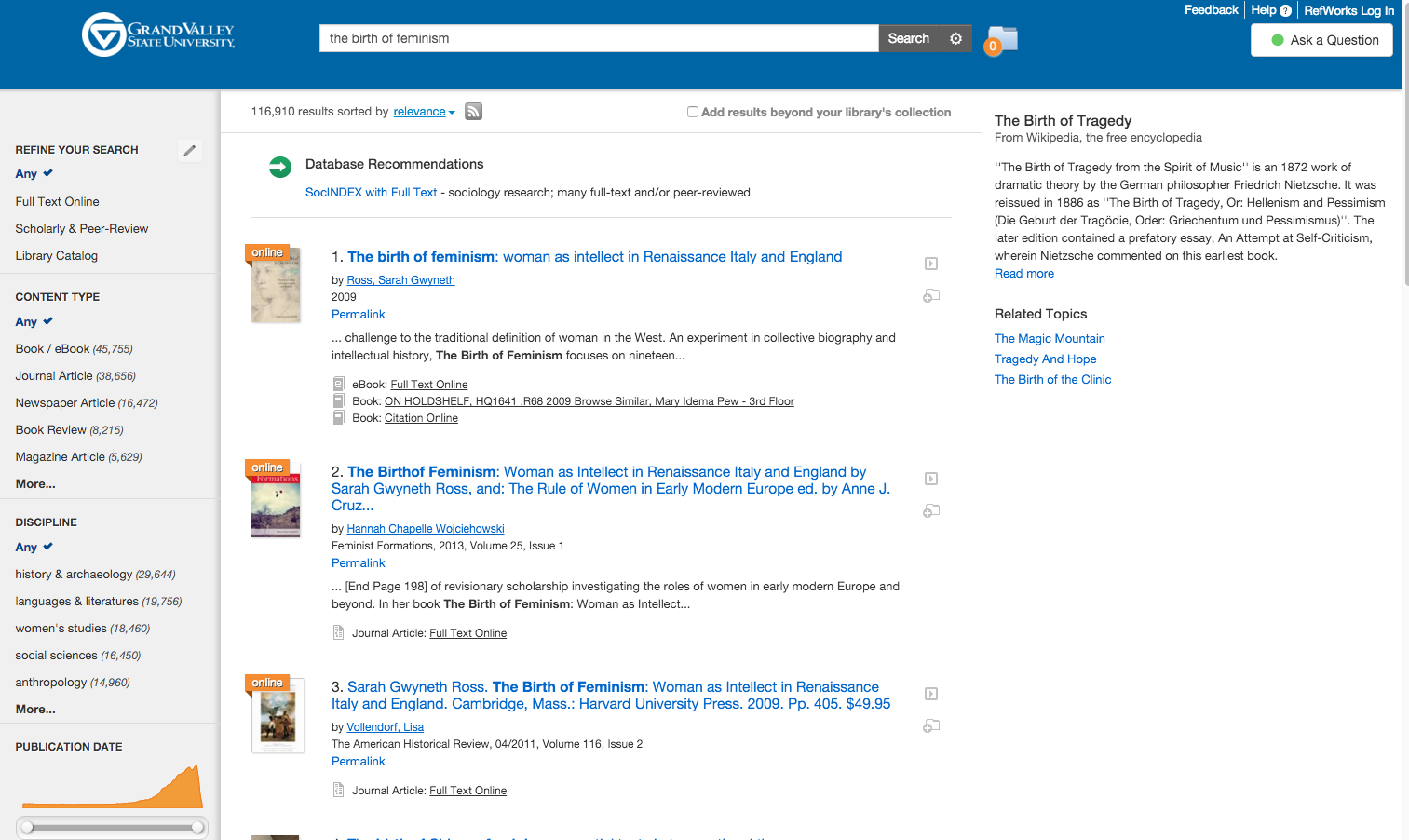
Or the tendency of the algorithm to latch on to phrasings like a Mad Libs search engine, like this search for the Sarah Gwyneth Ross' book Birth of Feminism that returned the Birth of Tragedy instead. This is what was behind the "women in the workforce" result my colleague Jeff showed me. You could also search for "heroes in the workforce" and get "women in the workforce."
If you want to examine an algorithm thoroughly, nothing beats collecting a lot of sample results, but there are other places to look for problems. I wish I knew who the mastermind behind this site was, but Damn You, Auto Suggest is a Tumblr with the subtitle of "Primo Knows Best. Auto-suggest failures from library catalogs and databases." You can even submit your own.
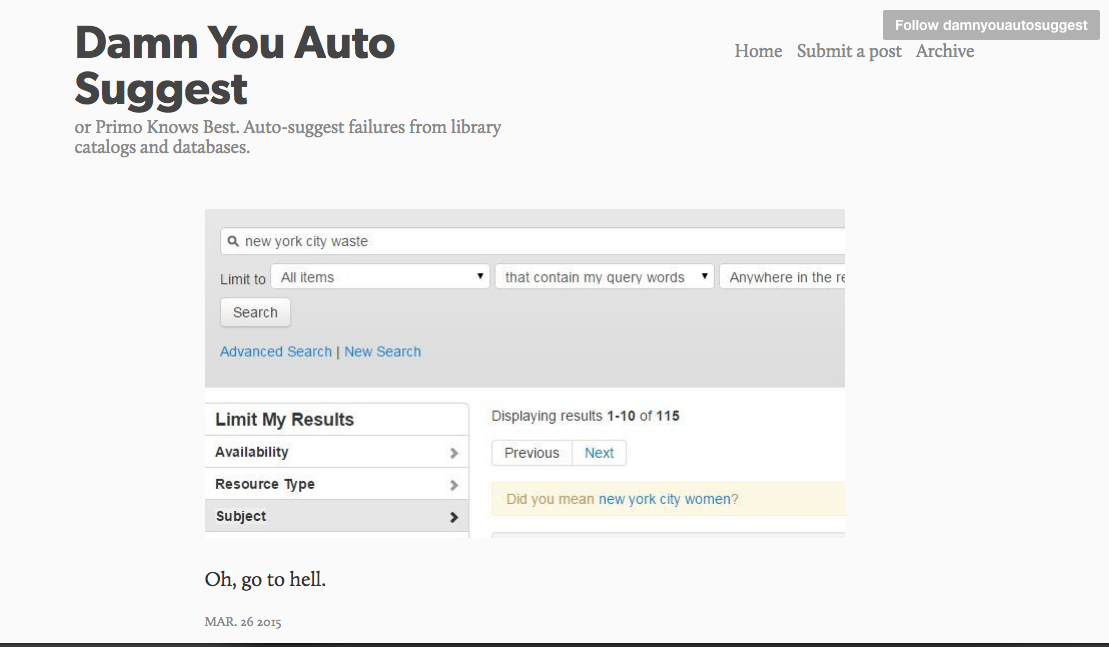
Here Primo suggests that a search for "New York Waste" should have been a search for "New York Women."
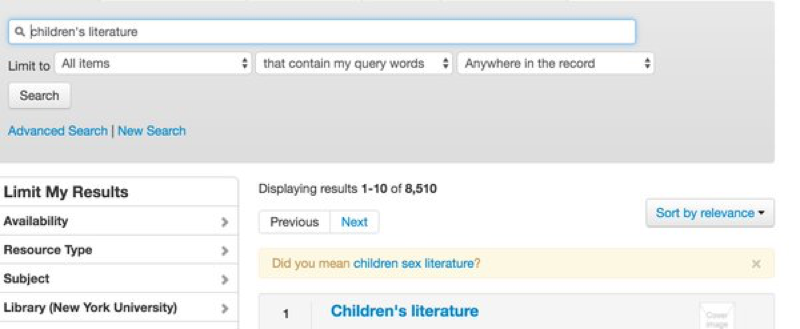
I've also been able to find problematic results from colleagues on Twitter, like this one that Nadaleen Tempelman-Kluit posted from Primo, where it thinks a search for Children's Literature could only be made better by transforming it into a search for Children's Sex Literature.
Inputs
&
Outputs
But algorithms aren't just code and inputs and outputs. They are used by people in order to do something else. We need to study those effects, too, and this is where my research is taking me.
Algorithms show and hide possibilities from users, suggesting what a search might really be about. In addition to asking what an algorithm looks at, and what kinds of results it returns, we need to ask how it affects the users who interact with the algorithm and its results. This is where ethnography and user research can come in. I will be talking to users, and running ethnographic experiments over the next year to better understand the impact that algorithmic outputs - both good and bad - have on learning and research.
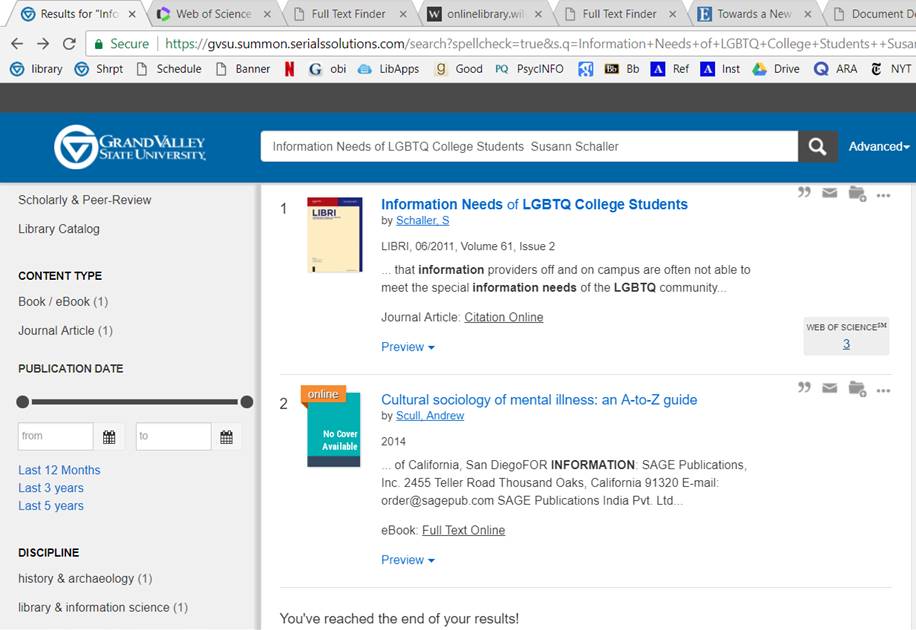
Here is a result that was shared with me by one of our users. It's a known item search for a book on the information needs of LGBT youth that returns only 2 items: the book and a guide to "mental illness."
As a researcher, results like these are often the ones that expose the inner workings of the algorithm more clearly. I can look at the metadata for that guide to mental illness and try to reverse engineer how it got there. They are like glitches in the Matrix.
But for the user who was searching for this book? What was the impact of seeing these books next to each other? Looking at inputs and outputs alone won't tell us how these results affect our users. Merely returning some relevant results isn't good enough. What we show (and don't show) matters.
These are challenging, scary, ethical issues. But library search tools are sold as neutral, objective places for learning and research. That is not the case, and part of the reason for auditing our algorithmic tools is to correct this kind of "objective" marketing, but also to work with vendors to improve the algorithms.
A word on the responsibilities of vendors. If your search tool reinforces and reproduces systemic racial, gender, religious, or other biases—it doesn't matter if you "didn't intend" to build a system with those biases. That's what you system does. It is your responsibility to make a system that is fair for all users. Your responsibility doesn't end when we go live with your tool.
But these search results are also the most visible and used parts of our library websites, and so they speak to our users about our values. Recently my fellow Weave Journal of Library User Experience editor Angela Galvan gave the keynote at VALA in Melbourne. She noted "Glitches are the unintentional exposure of values." For those of us who study algorithms, problematic results give us a clearer window into what an algorithm values. But our users will read that as what we in the library value. It is our responsibility to ensure that the values we claim to have are what are reflected in our tools. Our responsibility doesn't end when we sign the license agreement.
Now I'm going to try to recruit you to study the algorithms in your library systems. These algorithms are not affected by some of the most challenging parts of researching commercial search algorithms.
For one, the pressures of capital and wealth creation are not as direct as in an advertising-supported search tool like Google. There are (theoretically) no ads in our discovery services. Libraries are the paying customer, not the end user.
Because libraries are licensing this software, we expect that the vendor won't experiment with new features in our live discovery systems. And as of this moment, none of the vendors appears to be using machine learning algorithms to personalize search results for our users. (It will get there, but some of them are using tables for layout, so I think we're safe for a bit.) We can be pretty sure that all our users are seeing the same results for the same searches (except for some differences in on-campus and off-campus searches.)
And the content these search tools index isn't written to be searched in a search engine like web content. Much of it is written without worrying whether anyone will or can read and make sense of it, let alone a search engine. So when a result appears in a search, we can be reasonably sure it is there because of the algorithm, not manipulation on the part of an Assistant Professor of Botany.
On the other hand, discovery systems have challenges that are not as common in other algorithmic systems.
The most obvious is that search results from my discovery instance won't be the same for yours, because of the different collection practices of our institutions. This might not affect the "supporting" algorithms that are sprinkled around the main search results, like Topic Explorer or related searches, but it definitely affects the results from your collection.
Trying to understand why something appears in a results set can be challenging, because items in a discovery service's index often blend all the varied metadata practices of hundreds or different database providers into one big, messy soup. Of course, they often have a more structured taxonomy, as well, but results may appear because one of your keywords matched a thesaurus entry for a subject term in an obscure database. This metadata opaqueness can complicate our understanding of how algorithms choose results.
-Finally, if you want to study a tool that isn't the one your institution subscribes to, you may be thwarted by the End User License Agreement for the discovery service. Both (EDS) EBSCO discovery service and OCLC's Worldshare prohibit the search interface from being used by "unauthorized users," which is basically everyone but currently affiliated students, staff, faculty, or patrons at the subscribing institution.
Even if you could use the interfaces, none of us has the time to manually search and record results, so we'd ideally write a script to do this for us. But the license agreement may prohibit this, as well. (The Computer Fraud and Abuse Act is also so broad that even if the EULA didn't prohibit this, you might be in legal trouble from scraping results anyway.) If you subscribe to a service, you may be able to collect the results with a script in the guise of collecting usage data. That's what I did with Summon.
(A quick point of order: I am not a lawyer and this was not legal advice.)
So, here's my pitch: help me and all of us better understand our library discovery algorithms. If you're an authorized user, or a representative from EBSCO or OCLC, I'd love to talk with you. The license agreements say I can't use the tools, but they never said anything about me asking another authorized user to collect search results.
Better yet: dive in yourself and examine the algorithms, inputs, and outputs; talk to users, and share what you learn.